TL;DR
Intro. A “dependency cooldown” tells your resolver to ignore releases newer than \(N\) days, on the theory that the community will catch bad releases before you adopt them. In an April 2026 post, Astral laid out their internal security posture and listed cooldowns as one of the layers they lean on. It sounds cautious. It is in fact an unusually expensive hedge that optimizes for the wrong failure mode, deadlocks with the tools that protect you from the actual high-frequency failure mode (CVEs), and cannot be rescued with a user-level override.
Argument. Reason from first principles about what can actually happen to a dependency, and a flat pre-resolver cooldown is dominated by buffering later in the pipeline (at audit time, at merge time, at staging). Cooldowns trade a certain cost, extended CVE exposure every time a fix lands, for a speculative benefit, dodging fast-yanked malicious releases, that lockfiles, hashes, and staging already cover. A Monte Carlo simulation of the cost model (backed by a closed-form analytical check to machine precision) puts the break-even risk ratio \(I_{\text{attack}} / I_{\text{cve}}\) at roughly 12,000 for an 8-day cooldown. For a typical non-financial-critical service, that is nowhere close, and the policy loses.
Caveat. The math flips at high enough stakes. At \(I_{\text{attack}} / I_{\text{cve}} \geq 10^5\) (think: payments, custodial crypto, identity), a real cooldown does pay. The right answer for those teams is not “no cooldown” but “the least bad variant of one”, because the word “cooldown” today flattens eight different policies into a single switch and the default switch is the one that loses. Sections 8 and 9 name the alternatives.
Conclusion. Adopt fast. Verify hard. Buffer late. If you truly need a window in the resolver, do not reach for the flat one.
🧮 Reproduce the numbers. Every number in this post (break-even ratio, compromise probabilities, the cooldown sweep, the “one compromise every 69 years”) comes from a self-contained Python script. It runs in ~3 seconds via
uv run(PEP 723 inline metadata, numpy-only), asserts the Monte Carlo matches the analytical closed form to within 0.002, and prints a full cost-model report.👉 Gist:
simulate_dependency_cooldown.py+ captured outputChange any parameter (\(\lambda_{\text{cve}}\), \(r_{\text{attack}}\), the detection-delay mixture, your audit latency) and re-run. If you disagree with the conclusion, disagree with the parameters, not the math.
0. What this is not
This is not an argument against Astral’s broader security posture, most of which is excellent: trusted publishing, sigstore attestations, immutable releases, pinned actions, no caching during releases. Those layers genuinely move the needle. It is also not an argument against putting latency between a release and your production code. There should be latency. The question is where in the pipeline that latency earns its keep. A cooldown places it before the resolver, which turns out to be the worst possible spot: it blinds the resolver to CVE fixes, deadlocks with live-DB auditors, and duplicates protections that lockfiles and staging already provide. Every other layer is strictly better at the job.
1. The scenario: CI goes red on a security fix
Start with the concrete situation that prompted this post. A typical modern Python upgrade pipeline looks like this:
uv lock --upgrade(respects cooldown)pip-audit(does not respect cooldown; queries live advisory DB)
A CVE lands on package X. The maintainers cut a patch release X+1 the same day. Your scheduled Dependabot run fires. Here is what happens next:
flowchart TD
A[uv lock --upgrade
exclude-newer respects cooldown] --> B[Resolver refuses
to see X+1]
B --> C[Lockfile pins X
vulnerable version]
C --> D[pip-audit queries
live advisory DB]
D --> E[Audit flags X
CI fails RED]
E --> F{Fix X+1?}
F -->|blocked by cooldown| B
F -->|wait C days| G[Window expires]
G --> A
There is no version constraint you can write to escape this. Pinning cryptography>=46.0.7 directly produces:
× No solution found when resolving dependencies:
╰─▶ Because only cryptography<=46.0.6 is available and your
project depends on cryptography>=46.0.7, we can conclude
that your project's requirements are unsatisfiable.
exclude-newer is a hard pre-filter on the catalog, not a preference. The solver never sees filtered versions, so user constraints cannot recover them. The cooldown and the auditor deadlock, and the only way to break the deadlock is to wait for the window to expire. During those days, CI is red and the scheduled PR cannot open.
This is not a tooling bug. It is the direct consequence of layering a “hide new versions” filter under a “check against live CVE data” auditor. The two policies are logically incompatible for the entire duration of every cooldown window in which a CVE lands. It will recur on every future CVE that ships inside the window. That’s the scenario. The rest of this post explains why it is structural, not fixable by clever configuration, and what to do instead.
2. What events can actually happen to a dependency
To reason about the scenario from first principles, start by enumerating the things a package version can actually experience. At any time \(t\), a released version is in exactly one of these states:
- Fine forever. The vast majority.
- Latent bug, discovered at \(t = D_{\text{bug}}\).
- Latent CVE, present all along, disclosed at \(t = D_{\text{cve}}\), fix released at \(t = D_{\text{cve}} + \varepsilon\).
- Malicious: supply-chain attack, discovered and yanked at \(t = D_{\text{mal}}\).
- Intentional breaking change, discovered via your own traffic at \(t = D_{\text{reg}}\).
Each class has its own detection-delay distribution, and they are wildly different.
| Class | Typical detection delay | Who notices |
|---|---|---|
| 🕷️ Supply-chain attack (typosquat, account compromise) | ⚡ hours to days | 🤖 scanners, community |
| 🐛 Bug / regression | 📅 days to weeks | 👥 early adopters + your traffic |
| 🔓 CVE disclosed against existing version | ⏳ already there; disclosure starts the clock | 🔬 researchers, vendors |
| 💥 Breaking change | 📅 days to weeks | 👤 users |
Same content, different lens. Plot each class on a (detection speed, blast radius) plane and a visual story emerges about where a cooldown can actually help:
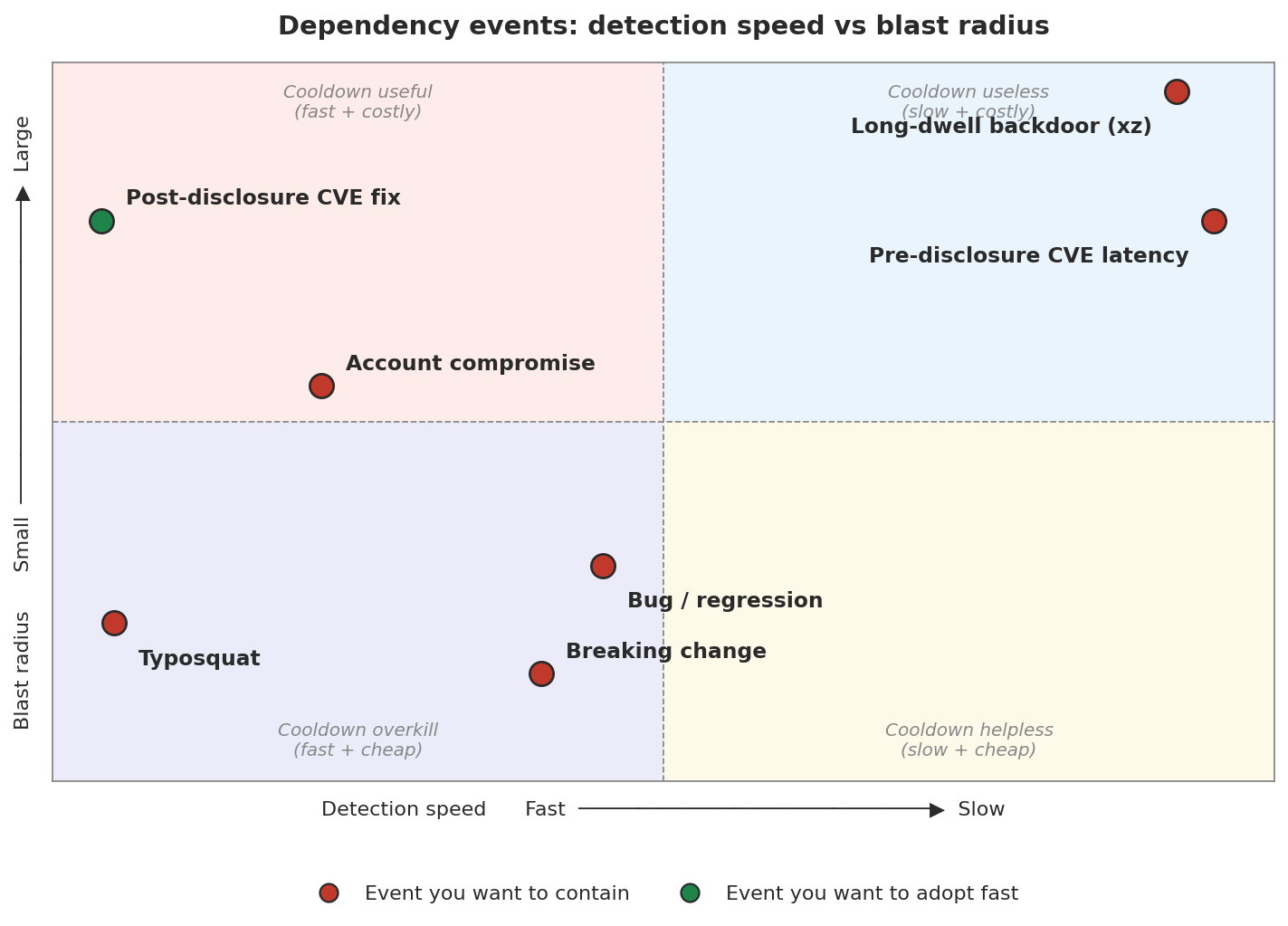
Chart generated by scripts/plot_dependency_events_quadrant.py (matplotlib, PEP 723 inline script, runs via uv run).
A cooldown lives entirely in the left half of the plane: it only bites events it can see, meaning ones with fast detection. Of the two left-half points worth catching, typosquats are already handled by new-dep review, and the post-disclosure CVE fix is exactly the event a cooldown delays, not protects against. Everything in the right half (long-dwell, pre-disclosure CVE latency) is invisible to any cooldown window you could reasonably set. The quadrant that a cooldown is supposed to own, top-left, is in practice almost empty once you subtract the events lockfiles and new-dep review already cover.
These distributions are the entire game. A cooldown is a bet on one of them: specifically, that \(D_{\text{mal}} < C\) often enough to justify the cost. Everything else is arithmetic.
3. The critical asymmetry: CVEs run the clock backwards
The naive cooldown argument treats “new version” as the risky event. For CVEs this is backwards, and this single asymmetry is the whole reason the scenario in section 1 exists. The real time sequence for a CVE is:
Your exposure window is \([0, N]\). It does not start when \(v_{\text{new}}\) ships; it started whenever you adopted \(v_{\text{old}}\), which was weeks or months ago. \(v_{\text{new}}\) is the end of your exposure, not the beginning.
A cooldown forces \(N \geq C\). That does not “delay risk.” It guarantees the extension of an exposure window you were already in. The cooldown is not caution; it is a commitment to stay vulnerable, paid up front, for every future CVE.
This is the core confusion cooldowns bake in: they conflate novelty with risk. A new version is novel; it is not (usually) risky. A not-yet-patched old version is not novel; it is (definitely) risky. The policy taxes the wrong axis.
4. The time sequence for a supply-chain attack
Now the event the cooldown is actually trying to protect against:
You are compromised iff \(N < D\). A cooldown with window \(C\) guarantees \(N \geq C\), so you are protected iff \(C > D\).
This is genuinely useful, but narrower than it sounds:
- Typosquats are detected in hours. Any cooldown catches them. But you weren’t going to install
requesstsanyway; this class is caught by new-dep review and pip’s warnings. - Compromised maintainer accounts (event-stream, ua-parser-js) get detected in 1–5 days typically. An 8-day cooldown catches them if you would have adopted the compromised version in those 1–5 days.
- Long-dwell attacks (xz-utils, the SolarWinds family) sit undetected for weeks to months. No reasonable cooldown catches these.
- Transitive compromises don’t care about your cooldown at all. The transitive is pinned in someone else’s lockfile and updates on someone else’s schedule.
So the cooldown defends against the middle band: medium-dwell compromises of packages you were about to adopt in the danger window. A real class, but not “supply chain attacks in general.”
5. Expected-cost math
Put numbers on it. Let me define the model cleanly before plugging in, because the sloppy version (where “rate” secretly contains a probability) leads to double counting.
Parameters. Over one year, for a typical non-trivial service:
- \(\lambda_{\text{cve}}\) = rate of CVE disclosures affecting packages in your dep tree. ~25/year for a non-trivial Python service.
- \(r_{\text{attack}}\) = rate of malicious releases published in packages you could plausibly adopt (before any mitigation). ~0.1/year is a reasonable guess for a team with lockfiles and new-dep review already in place.
- \(L\) = audit latency in days. One cycle (1 day) if you audit on every resolve.
- \(C\) = cooldown window in days (e.g., \(C = 8\)).
- \(N_0\) = your natural adoption delay. Weekly upgrade cadence means \(N_0 \sim \mathrm{Uniform}(0, 7)\).
-
\(D\) = detection delay for a malicious release, drawn from a mixture of exponentials reflecting the classes in section 4:
$$ D \sim 0.5 \cdot \mathrm{Exp}(1/0.5) \;+\; 0.3 \cdot \mathrm{Exp}(1/3) \;+\; 0.2 \cdot \mathrm{Exp}(1/60) $$(typosquats in hours, account compromises in days, long-dwell in months). - \(I_{\text{cve}}\) = cost of one vuln-day of known-vulnerable exposure. - \(I_{\text{attack}}\) = cost of one successful compromise. Both costs are in the same unit, so the quantity we really care about is the ratio \(I_{\text{attack}} / I_{\text{cve}}\).
Term (1): guaranteed CVE exposure. Each disclosed CVE costs you the time between disclosure and upgrade. A cooldown forces that time to be at least \(C\); auditing forces it to be at least \(L\). So exposure-per-CVE is \(\max(C, L)\). Annual cost:
Plugging in: \(\text{CVE}(0) = 25 \cdot 1 = 25\) vuln-days/year. \(\text{CVE}(8) = 25 \cdot 8 = 200\). The cooldown’s guaranteed CVE tax is the difference, \(\lambda_{\text{cve}} \cdot (\max(C, L) - L) \cdot I_{\text{cve}} = 175 \cdot I_{\text{cve}}\).
Term (2): residual attack cost. This is where the naive model went wrong. The clean decomposition is: a compromise happens iff you adopt before detection, i.e., \(N < D\), where \(N\) is your effective adoption delay. Without a cooldown, \(N = N_0\). With cooldown \(C\), the resolver refuses versions newer than \(C\) days, so \(N = \max(C, N_0)\). Annual attack cost:
No hidden probability inside \(r_{\text{attack}}\). The probability of compromise is computed from the model, not assumed.
Plugging in. For \(N_0 \sim \mathrm{Uniform}(0, 7)\) and the detection-delay mixture above, a direct Monte Carlo simulation (2 million samples, seed 42, results match analytical closed forms to four decimal places) gives:
So an 8-day cooldown prevents \(\Delta P \approx 0.145\) of attacks in absolute terms. Expected compromises per year:
The cooldown prevents about one compromise every 69 years.
Total cost. Combining both terms:
Break-even. Setting \(\text{cost}(8) = \text{cost}(0)\) and solving for the risk ratio:
In plain language: one compromise would have to be as damaging as 12,000 CVE-days of exposure for an 8-day cooldown to pay off at these parameters. For most teams, nowhere close. The math gets worse when you notice that term (2) is already mostly mitigated by lockfile hashes and new-dep review, which the cooldown does not improve.
The shape of the tradeoff. Sweeping \(C\) through common values (numbers taken directly from the simulation gist output, section “Shape of the tradeoff”):
| Cooldown \(C\) | CVE exposure | \(\Pr(\text{compromise})\) | Compromises prevented vs \(C=0\) | Break-even \(I_{\text{attack}} / I_{\text{cve}}\) |
|---|---|---|---|---|
| 0 days | 25 vuln-days/yr | 0.3406 | baseline | n/a |
| 🟢 1 day | 25 vuln-days/yr | 0.3134 | 1 per 368 yrs | 0 (free lunch: \(C = L\)) |
| 🟢 2 days | 50 vuln-days/yr | 0.2887 | 1 per 193 yrs | 4,814 |
| 🟡 5 days | 125 vuln-days/yr | 0.2354 | 1 per 95 yrs | 9,511 |
| 🟡 7 days | 175 vuln-days/yr | 0.2071 | 1 per 75 yrs | 11,234 |
| 🔴 14 days | 350 vuln-days/yr | 0.1612 | 1 per 56 yrs | 18,117 |
| 🔴 30 days | 750 vuln-days/yr | 0.1213 | 1 per 46 yrs | 33,064 |
Two things jump out. First, \(C = 1\) is genuinely free: it matches your audit latency, so CVE exposure does not move at all, yet it still catches an extra ~3% of compromises. If you must have a cooldown, that is the one that does not cost you anything. Second, break-even grows faster than linearly in \(C\): doubling the window more than doubles the risk ratio at which the cooldown pays off, because the CVE tax grows linearly while the remaining attack surface shrinks sub-linearly. Long windows get punished hard.
⚠️ Limits of this model. The detection-delay mixture, \(r_{\text{attack}}\), and the linearity of \(I_{\text{cve}}\) are priors, not measurements. Treat the break-even ratio as accurate to roughly one significant figure: “~12,000” could plausibly be 6,000 or 30,000 depending on what you believe about long-dwell tail shape, how bursty fast-yank detection really is, and whether CVE cost escalates non-linearly with exposure time. The model is also blind to transitive deps, fleet multipliers, operational toil, attacker adaptation, and catastrophic tail events that expected-value math systematically undersizes. These biases point in both directions and mostly cancel; the best place to push back on this post is to challenge the parameters, not the structure. What the model does not depend on: the CVE clock-asymmetry argument (section 3), the auditor/resolver deadlock (section 1), or the operational-debt modes (section 7). Those are qualitative, distribution-free, and robust.
6. Where to put the time buffer
The real question is not “should there be latency between a version shipping and prod running it.” There should. The question is where in the pipeline to put that latency. You have three choices:
| Buffer location | Fast CVE adoption? | Catches regressions? | Defends fast-yank attacks? | Deadlocks with audit tooling? |
|---|---|---|---|---|
| 🚫 Pre-resolver (cooldown) | ❌ no | ⚠️ weak, you hope the community flags it | ⚠️ narrow band | ❌ yes |
| ⚙️ Post-resolver, pre-merge (CI + audit + review) | ✅ yes | ❌ no | ✅ yes, via hashes | ✅ no |
| 🧪 Post-merge, pre-prod (staging bake) | ✅ yes | ✅ yes, real traffic | ✅ yes | ✅ no |
Pre-resolver buffering is dominated on every axis that matters for a typical service. There is one degenerate exception: \(C \approx L\), a cooldown matched to your audit latency. That setting costs nothing extra in CVE exposure (since \(\max(C, L) = L\)) and still catches a few fast-yank attacks. It is the only version of a cooldown that is strictly non-harmful, and it is not what anyone means when they enable one. Everything larger starts paying the CVE tax described in section 5.
If you have a weak argument for buffering earlier, you have a strictly stronger argument for buffering later. Staging bake is the killer comparison. It uses your own traffic to detect regressions. That is a higher-fidelity signal than “the community didn’t yank it yet”: you know whether your code, your workload, your configuration breaks. The community cannot tell you that. A cooldown pretends community vigilance is a substitute. It isn’t.
7. Additional failure modes
Beyond the deadlock, cooldowns accumulate operational debt:
Per-package allow-lists rot. uv offers exclude-newer-package to exempt a package from the cooldown. Every CVE that lands in the window requires someone to add a line. Nobody removes the lines later. Within a year the allow-list covers every security-critical package you have (i.e., exactly the ones the cooldown was supposed to protect), and the cooldown applies only to packages where it has no upside.
Silence is not safety. When a release is yanked, you want to know now, because you probably already adopted it in prior weeks. A cooldown-based policy hides yanks until the window expires. You get neither warning nor action.
False security against the wrong threat model. Cooldowns optimize for malicious-release attacks you probably mitigate via lockfile hashes, while ignoring account compromise, dependency confusion, transitive bad actors, and long-dwell attacks. The marketing matches the real threat landscape poorly.
Staleness tax compounds. Over a year, an 8-day cooldown means every production service you ship is, on average, 4 days behind the ecosystem. Every bug fix, every performance improvement, every compatibility patch arrives late. None of that delay makes you safer; it just means you run older code continuously, forever, by construction.
8. When cooldowns actually win
Every model has a regime where its conclusion flips. Sweeping the total cost function from section 5 across cooldown windows at different risk ratios \(I_{\text{attack}} / I_{\text{cve}}\) reproduces the simulation output:
| \(I_{\text{attack}} / I_{\text{cve}}\) | Optimal \(C\) | What kind of service |
|---|---|---|
| 🟢 \(10^2 - 10^4\) | 1 day | typical web service, internal tools, SaaS backend |
| 🟡 \(10^5\) | 14 days | high-value platform: fintech, identity, custodian |
| 🔴 \(10^6\) | 90 days | catastrophic-breach-class: payments, custodial crypto, critical infrastructure |
Read this as: a team that genuinely models one compromise as equivalent to 100,000 CVE-days of exposure should run a real cooldown. At that risk ratio, the 175-vuln-day tax is cheap insurance. For everyone else, it is not.
The break-even \(I_{\text{attack}} / I_{\text{cve}}\) for an 8-day cooldown under the default detection-delay mixture is approximately 12,000. Below that, no cooldown (or \(C \approx L\)) wins. Above it, cooldowns start to pay and should grow with the stakes.
Most teams are nowhere near 12,000. Estimate yours honestly before you adopt.
9. The word “cooldown” needs better semantics
Part of the problem is that the term “cooldown” flattens at least eight distinct policies into one switch. Each has a different cost profile and a different threat model. Naming them separately turns a sterile debate about “cooldowns yes/no” into a design question about which filter you actually want.
1. Flat pre-resolver cooldown. The thing uv’s exclude-newer ships today. Hides every release younger than \(C\) days from the resolver. Uniform window, uniform package set. This is what the rest of the post argues against.
2. Audit-matched cooldown (\(C = L\)). Set the cooldown equal to your audit latency. Zero CVE tax, catches the hours-class fast-yank attacks for free. The only version that is strictly non-harmful. Almost nobody configures this because it feels uselessly small. It isn’t.
3. Additions-only cooldown. Apply the cooldown only to packages not already in your lockfile. The threat model the cooldown actually addresses is malicious new adoption; upgrades of already-vetted packages are a different attack surface. This isolates the benefit without the CVE tax on upgrades. Needs tooling support; exclude-newer-package can fake it via inverted allow-lists.
4. Release-cadence-adaptive cooldown. Window inversely proportional to recent release frequency. Packages that publish weekly have dense community traffic and short effective detection delays, so the cooldown contributes nothing and should be near zero. Packages that publish yearly have almost no community scrutiny, so the long-tail regime from section 4 applies and a longer window can matter. Addresses the long-dwell failure directly instead of picking one number for the whole dep tree.
5. Canary cooldown (fleet-staged adoption). Upgrade 10% of your fleet on day 1, the rest on day \(C\). Compromises are detected by your telemetry on the canary before the full rollout. This is just canary deployment applied to dependencies and it subsumes what a cooldown pretends to buy, because the detection signal is your actual traffic rather than community vigilance. Section 6 already argues this is a higher-fidelity signal.
6. Advisory-aware cooldown (the resolver fix). The deadlock in section 1 exists because the resolver and the auditor do not talk. An advisory-aware resolver polls the CVE database at resolve time and exempts any version that fixes a listed vulnerability from the cooldown. The policy would read: “hide fresh releases unless the fresh release is a security patch.” That is the only form of cooldown whose failure mode is not a guaranteed CVE-exposure extension. It does not exist in any mainstream Python resolver today. It should. If I had one practical ask of the uv team, it would be this.
7. Information-theoretic cooldown. A cooldown is a bet that community inaction provides meaningful signal about package safety. Ask the prior question: how many of the packages in your dep tree actually have a community watching? The top ~1,000 PyPI packages have eyes on them. The long tail does not. For a package with no community watchers, a cooldown provides exactly zero bits of information, because the absence of a yank means nothing, since nobody would have yanked it anyway. An honest cooldown implementation would apply only to packages with a measurable watcher population (GitHub stars above a threshold, weekly downloads above a threshold, recent security-advisory activity) and skip the rest. Most dep trees would end up with a cooldown on maybe 50 packages, not 500.
A variant I originally listed and then cut: “differential cooldown by blast radius”, where security-sensitive packages get \(C = 0\) and utility packages get a longer window. It sounds principled, but the end state is identical to the allow-list rot failure mode from section 7: the cooldown applies exactly where it has no upside and skips exactly where it would matter. Steelmanning it with “utility packages have higher typosquat rates” doesn’t rescue it, because variant 2 (\(C = L\)) already catches typosquats for free and your new-dep review (section 10) catches typosquat additions. Freezing the rot pattern in configuration is still the rot pattern.
Options 2 through 7 are all strictly better than option 1 in at least one dimension, and some of them strictly dominate it. If your package manager shipped any of them instead of option 1, the argument in this post would be much narrower and the Astral practice much more defensible. The problem is that when a blog post, a config flag, or a pipeline template says “cooldown”, everyone reads option 1, and option 1 is the one that loses.
10. What first principles actually say
Work the sequence of events again, but from the defender’s perspective. You want each class of risk handled at the point in the pipeline where detection is cheapest and most accurate.
| Threat | Best detection point | Cost |
|---|---|---|
| 🔓 CVE fix needed | as soon as disclosed | 🔍 audit on every resolve |
| 🐛 Latent bug / regression | under your own traffic | 🧪 staging environment |
| 🕷️ Fast-yank supply-chain attack | at lock time, on new additions | 🔐 lockfile hashes + new-dep review |
| 🐚 Long-dwell supply-chain attack | via advisory subscription and SBOM monitoring | 📡 targeted vigilance |
| 💥 Breaking change | in CI against your integration tests | ✔️ tests |
Notice what’s missing from this table: a time window during which the resolver pretends new versions do not exist. That policy does not appear in any row because no row benefits from it. Every legitimate concern has a better home.
The operational rules that fall out:
- Lockfiles with hashes, always. This is the supply-chain defense that actually works. Use
uv sync --lockedor--frozenin CI and deploy paths1. - Audit on every resolve, block on HIGH/CRITICAL. Drives
audit_latencyto one cycle. - Upgrade frequently. Short
Nbetween CVE disclosure and your patch. Frequency is safety, not risk. - Staging bake for regression detection. Your traffic beats community traffic for your workload. This is the same “recovery beats prevention” logic that falls out of first principles in devops.
- Manual review on new dependencies only. Upgrades of existing deps are a small attack surface. Additions are the hot spot.
- Subscribe to advisories for critical-path packages. Ten packages, maybe. Targeted vigilance is cheap and has no deadlock cost.
- Pin manually when you truly need to be paranoid about one package. Surgical. No collateral damage. No allow-list rot.
A team I work with recently ripped out an 8-day flat cooldown from a Python monorepo and replaced it with pip-audit on every PR plus CODEOWNERS review on any pyproject.toml edit. The deadlock stopped recurring, CVE fixes now ship same-day, and the human-review budget landed on the one surface that actually matters: new dependencies.
These rules are scoped by the caveat in section 8. At high enough stakes, you should layer one of the smarter variants from section 9 on top; at typical stakes, the rules above are the whole answer.
11. Summary
| ✅ Pros of cooldowns | ❌ Cons of cooldowns |
|---|---|
| ✅ Catches fast-yank supply-chain attacks in a narrow window | ❌ Guarantees extended CVE exposure every time a fix lands |
| ✅ Trivial to enable | ❌ Deadlocks with every live-DB vulnerability scanner |
| ✅ Supported in most package managers | ❌ Cannot be overridden by user version constraints |
| ✅ Feels cautious | ❌ Per-package allow-lists accumulate permanently |
| ❌ Hides yank signals during the window | |
| ❌ Wrong threat model: protects against a narrow band that lockfiles + review already cover | |
| ❌ Silently delays every improvement, 100% of the time | |
| ❌ Confuses novelty with risk |
The flat pre-resolver cooldown that today’s package managers ship optimizes for the wrong point in the pipeline, against the wrong threat model, at the cost of a certain and recurring operational debt. The real defense is layered: fast audits in CI, tight lockfiles with hashes, a staging bake against your own traffic, and manual review on the narrow surface where it pays, new dependencies. Once those layers exist, flat cooldowns add nothing but delay at typical risk ratios. If you need more than that, reach for one of the smarter variants in section 9, canary rollouts or advisory-aware resolvers before flat windows. Caution should be cheap when the thing you are cautious about is bad, and free when it is good. Flat cooldowns are instead expensive every day, in exchange for a contingent payoff that, for most services, the math cannot justify. If a policy makes you feel safer every day while making you measurably less safe every week, retire it and replace it with one that actually pays.
Adopt fast. Verify hard. Buffer late.
References
- Simulation gist:
simulate_dependency_cooldown.py+ output. Companion Python script backing every number in this post, plus the captured run output. Reproduce or challenge the results end-to-end. - Open source security at Astral, William Woodruff, April 2026. The original post this analysis responds to.
- uv:
exclude-newerdocumentation. The cooldown mechanism analyzed in this post. - pip-audit. Live advisory DB auditor referenced in the deadlock example.
- event-stream incident (2018). Canonical medium-dwell account-compromise supply-chain attack.
- xz-utils backdoor (CVE-2024-3094). Long-dwell supply-chain attack no cooldown could catch.
- First Principles: DevOps. Related post on why feedback loops and recovery beat prevention in operational systems.
-
--lockederrors ifuv.lockis out of sync withpyproject.toml, catching the case where someone edits a dependency and forgets to re-lock.--frozengoes further: installs exactly what the lockfile says and never readspyproject.tomlat all, so the deploy path is fully deterministic. A bareuv syncis fine for local development because uv does not consider a lockfile outdated just because new versions shipped upstream; the lockfile stays stable until someone explicitly runsuv lock --upgrade. ↩